How Prime Video Knows Who’s On Screen: System Design Behind X-Ray
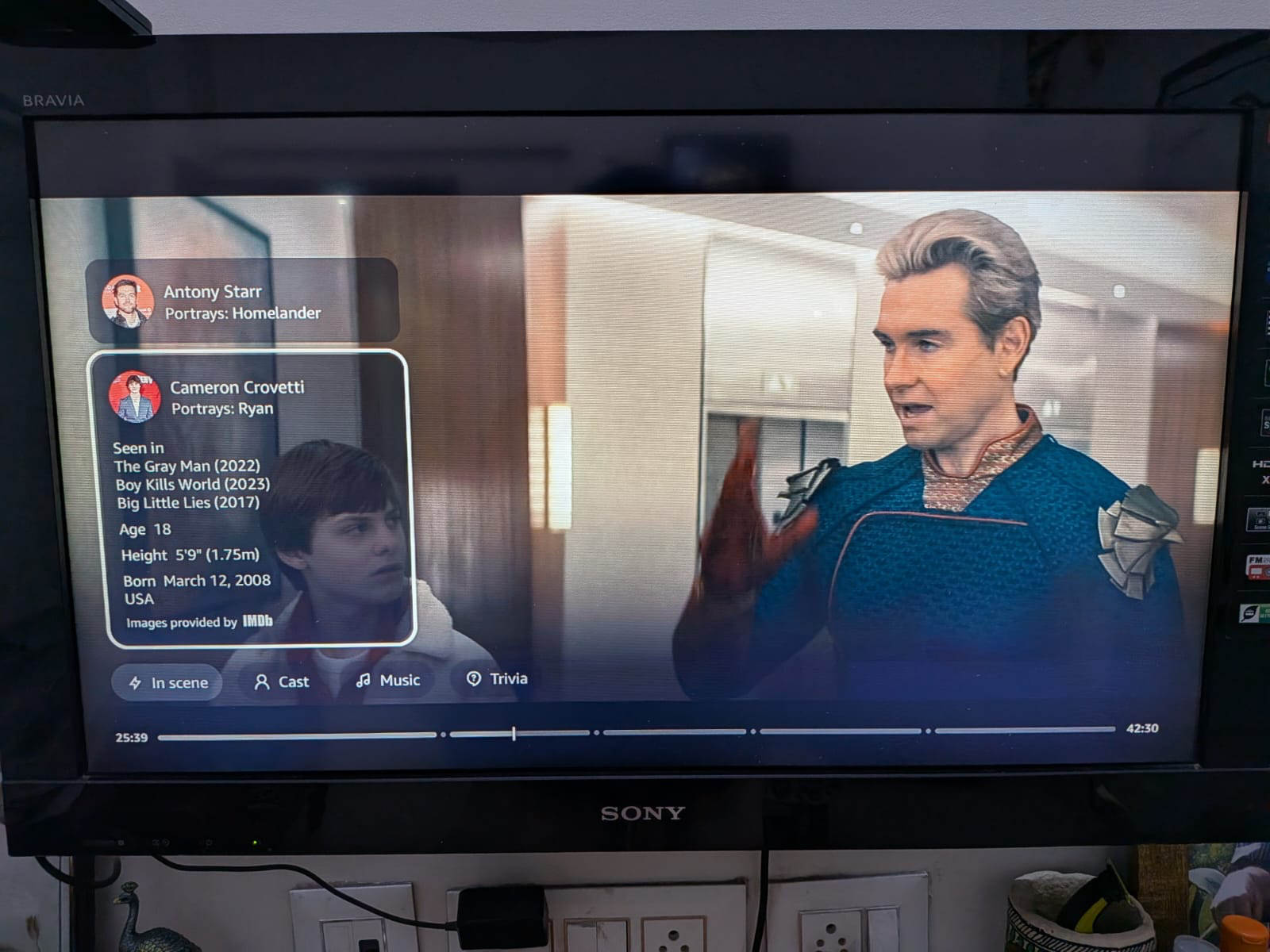
I was watching the season finale of this show - you know, one of those crucial moments where everything's about to go down. A character I hadn't seen in episodes suddenly appears on screen, and I'm sitting there thinking: wait, who's this? What was their arc? In the old days, I'd pause, grab my phone, fire up IMDb, and completely lose the tension of the moment.
But this time, I just tapped the screen. Instantly - cast member name, character, previous episodes they appeared in, even the music playing. It was seamless. Elegant. Just there.
Now, I know Amazon's Prime Video X-Ray exists. I've used it before. Everyone who watches Prime Video knows what it does: shows actors, characters, music, and trivia without interrupting your viewing. But this time, I got curious. Not about what it does—that part's obvious. But how? And more importantly, why did they ship this? What engineering decisions led to something so simple feeling so inevitable?
From an engineering perspective, this feature is deceptively hard. It requires synchronizing metadata with exact timestamps in a video, handling millions of titles with varying metadata quality, running real-time queries on massive datasets with sub-second latency, and operating at streaming scale without infrastructure melting.
What's remarkable isn't just that Amazon built this—it's that they chose a design that seems fundamentally at odds with how we typically think about distributed systems. This is the story of those tradeoffs and why they were right.
The Problem: Metadata at Streaming Scale
Prime Video has over 900,000 titles. For each moment in every title, viewers want metadata: who's on screen, what song is playing, what's happening in the plot. This is fundamentally a lookup problem, but not a simple one.
At scale, the challenges are immense. A 2-hour movie is 7,200 seconds. Multiply by 900,000 titles and you're at billions of data points. Metadata quality is inconsistent, queries must be fast, and the system must be cost-effective.
First Principles: Naive Ideas and Why They Fail
Consider three approaches and why they fail:
Approach 1: Real-Time Database Queries - Store all metadata in a traditional database and query on-demand. With billions of records, you'd need massive infrastructure, and peak loads would destroy your database.
Approach 2: Pre-Compute Everything Into Cache - Pre-compute full timelines for each title. Storage becomes prohibitive at scale - petabytes of infrastructure. Plus, updates become complex.
Approach 3: Push Metadata to the Client - Send entire metadata timelines to user devices. But metadata changes over time (music licensing, actor corrections), and large files slow app startup.
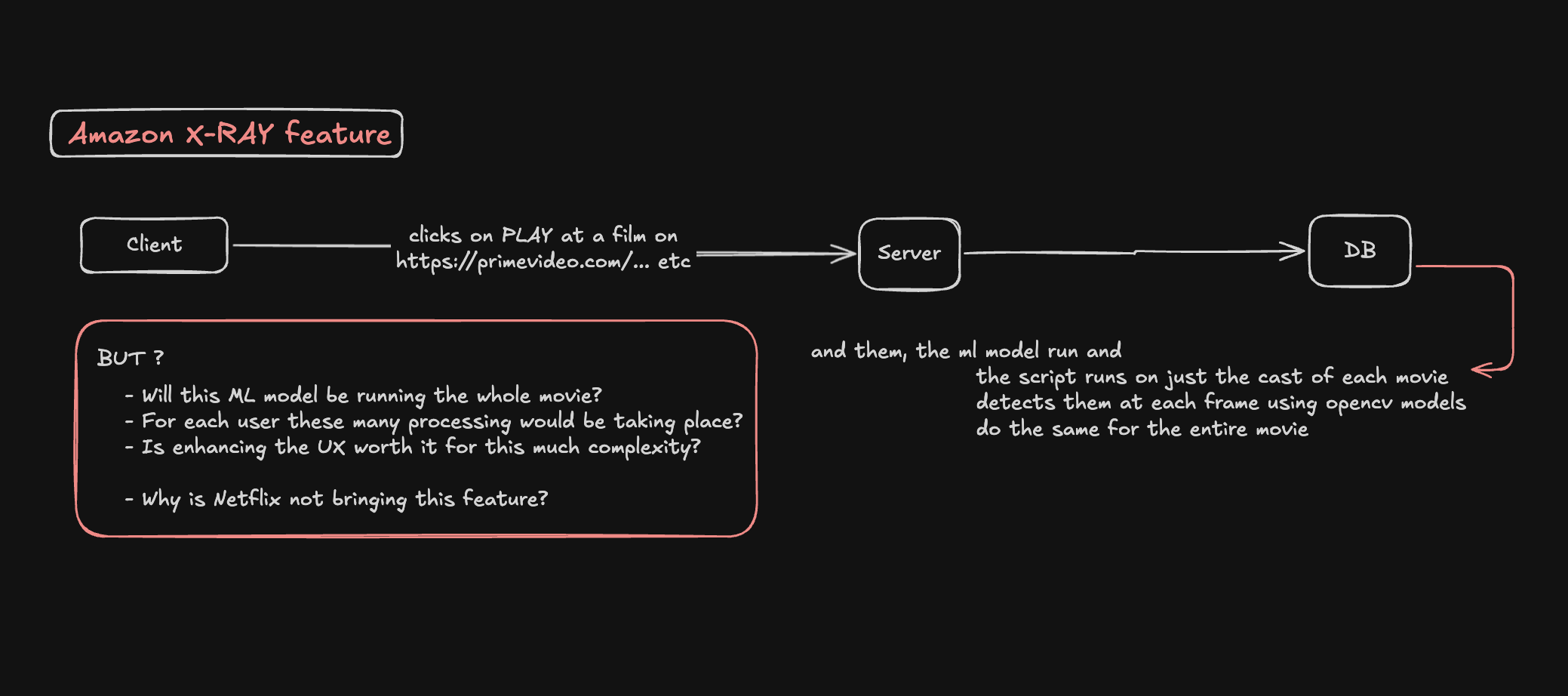
All three approaches fail because they optimize for the wrong thing. X-Ray needed a design that optimized for: low server cost, high reliability, fast reads, and easy metadata updates.
The Actual Design: Three-Layer Architecture
Amazon's solution splits the problem into three layers, each optimized for its specific role.
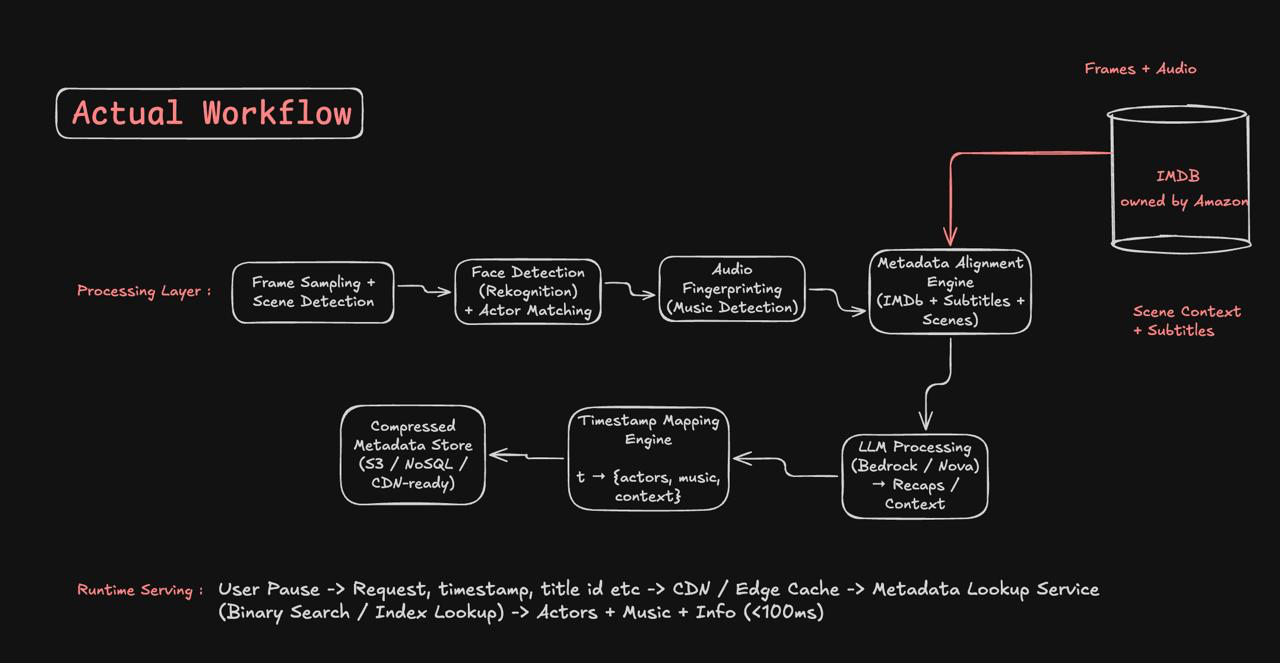
Layer 1: Offline Processing
Before a title launches, metadata is processed in batch jobs. These jobs ingest all available metadata (cast, crew, music, trivia), align metadata to specific timestamps, validate and deduplicate information, and generate index structures optimized for fast lookups.
The key insight: all the hard work happens once, offline. No real-time processing, no expensive compute during playback. This is why the system scales so well.
Layer 2: Metadata Storage
Processed metadata is stored in a way optimized for the query pattern: "give me metadata for title X at timestamp T, as fast as possible."
Rather than a traditional database, X-Ray uses a custom format. For each title, metadata is serialized into a compact, index-friendly structure. Because it's immutable after creation, it can be aggressively cached, distributed across CDNs, and cached on clients.
Layer 3: Runtime Execution
When a viewer scrubs to timestamp T:
- Client sends request: "title X, timestamp T"
- Server loads the pre-computed metadata structure (from cache if available)
- Binary search on the timestamp index: O(log N) operation
- Return relevant metadata (cast members, music, trivia)
Real Product Behavior: What The User Sees vs What Happens
User action: Watching Interstellar, scrubs to 1:28:45 (the tesseract scene), taps the screen.
Behind the scenes: Client request goes to nearest edge server (likely cached from other viewers). Server does binary search on timestamp 1:28:45 in the pre-built index. Returns: "Murph" (character), "Jessica Chastain" (actor), "Hans Zimmer - Interstellar Theme" (music), and other metadata. Response: sub-100ms, minimal server resources.
Because this is a read-heavy system with immutable data, it can be cached aggressively at every layer: CDN level, server cache (Redis), and client cache. After the first request for a title, subsequent scrubs often hit client cache or edge cache.
The Tradeoffs: Engineering Decisions and Their Costs
Tradeoff 1: Accuracy vs Cost
X-Ray metadata is only as good as the input data. A title with incomplete metadata will have gaps in X-Ray.
Amazon could have built a system using computer vision to detect actors, audio analysis to identify music, and ML to generate metadata. This would be more "accurate" but would require massive infrastructure, complex ML models, high latency, and ongoing maintenance.
Instead, Amazon chose simpler: rely on human-curated metadata. This is cheaper, more accurate (humans don't make ML-style mistakes), and easier to maintain. The tradeoff: some titles have sparse metadata. That's acceptable.
Tradeoff 2: Storage vs Speed
Pre-computed metadata is fast to query but costs storage. You could reduce storage by recomputing on-demand, but that's slow.
Amazon chose to store pre-computed metadata structures and get sub-100ms queries. Why? Storage is cheap, latency is a product quality issue, and immutable data is easy to cache and replicate.
Tradeoff 3: Automation vs Manual Systems
X-Ray metadata depends on accurate timestamp alignment. Amazon uses a hybrid: automated alignment (scripts match metadata to video), manual verification (for popular titles), and crowdsourcing (IMDb users suggest corrections).
The hybrid approach costs money upfront but ensures quality for popular titles.
Why It Was Worth Shipping: Business Meets Engineering
1. It Removes Friction: The question "who is that actor?" is one of the most common interruptions during viewing. X-Ray answers it without leaving the app.
2. It's a Competitive Advantage: Being first matters in building viewer habits and loyalty.
3. It Unlocks Data: Every X-Ray interaction is a data point. Amazon learns what moments people find interesting, which actors viewers are curious about, and which music gets reactions.
4. The Engineering Is Efficient: The offline-processing approach meant launching X-Ray didn't require massive infrastructure overhaul. High product value with manageable engineering cost.
Why Netflix Cannot Do This?
Netflix has the scale, the engineering talent, and the infrastructure to build something like X-Ray. So why haven't they? It's not a capability gap - it's a dependency gap.
The IMDb Advantage: Amazon owns IMDb. This isn't a coincidence. When you're building frame-by-frame metadata for movies and shows, you need authoritative cast information, episode data, and character arcs. IMDb is that source of truth. Netflix would have to negotiate with IMDb for structured, realtime access to this data - or build their own alternative. Either path is costly.
Licensing Complexity: X-Ray includes music identification. Amazon has licensing agreements in place. Music metadata - who performed what, which songs played when - requires clearances and partnerships. Netflix would need to negotiate similar deals, which adds cost and complexity.
Content Ownership Model: Netflix licenses most of its content from studios. Amazon Prime Video has more original content. For originals, metadata alignment is easier - you control the production data. Licensed content requires retroactive metadata curation, which is harder at Netflix's scale.
The Economics Don't Work Yet: For Netflix, X-Ray is a nice-to-have. For Amazon, it's a strategic differentiator that justifies the investment because they own the underlying metadata infrastructure. Netflix needs to show subscription growth - X-Ray doesn't directly drive that metric.
None of this means Netflix couldn't build it. It means the cost-benefit calculation is different. That's how platform advantages compound - not through raw capability, but through structural positioning.
Key Takeaways
1. Separate Concerns Ruthlessly: Metadata alignment is hard; serving it at scale is easy. By separating these problems, Amazon solved both efficiently.
2. Immutability Is Underrated: Immutable metadata files enable aggressive caching and distribution. Mutable systems require complex invalidation logic.
3. Tradeoffs Are Explicit, Not Hidden: Amazon could have built a "perfect" system using ML-generated metadata, but instead chose simpler human-curated metadata. The key is understanding the tradeoff explicitly.
4. Product Value Justifies Engineering Investment: X-Ray works because it removes friction from the viewer experience. Always ask: does this solve a real problem?
5. Scale Thinking Changes Architecture: At small scale, you might query metadata in real-time. At Amazon's scale, that's infeasible. The architectural shift to offline processing is a necessity.
X-Ray Gen AI: The Next Evolution (Recap & Beyond)
As AI models become more sophisticated, Amazon has been experimenting with using generative AI to enhance X-Ray. The idea: instead of just showing you who's on screen and what's playing, why not generate dynamic recaps?
Imagine pausing at the end of a complex scene and seeing an AI-generated summary of what just happened, character motivations, plot implications—all in real-time. This is where X-Ray Gen AI comes in, combining the structured metadata of traditional X-Ray with the creative synthesis of generative models.
This represents the next architectural shift: from "serve pre-computed data" to "generate contextual intelligence on demand." It's a fascinating bridge between the deterministic world of indexed metadata and the probabilistic world of language models.
The engineering challenges are completely different from what we've discussed. You're no longer bound by pre-computed metadata—you're making real-time ML inferences while maintaining latency budgets and controlling hallucinations. That's a story for another deep dive.
Closing: The Underrated Art of Doing Less
Engineering blogs often celebrate technical complexity. X-Ray represents something equally valuable: the art of solving a complex problem with simplicity.
Prime Video could have built a real-time metadata inference system using computer vision, NLP, and audio analysis. Instead, they separated the problem into layers and solved each one independently.
That's the real engineering: knowing which problems to solve offline, which to solve with caching, and which to not solve at all.
References & Further Reading
- AWS X-Ray Recaps - Official-ish AWS angle (modern AI)
- Understanding Amazon Prime Video's X-Ray Feature - Technical deep dive
- Prime Video X-Ray - Experience it yourself